To non-experts, it can be difficult to distinguish term "rule engine" from the many other terms, including "production system", "inference engine", and "expert system", that are often used to describe very similar concepts. These terms do not all have the same meaning, but as usage seems to vary widely throughout industry, academia, and the lay public, we will not attempt to describe the various nuances of this issue. In general, we will refer to a rule engine. (The Drools project refers to Drools as a business rule management system as well as a rule engine. However, others refer to Drools more technically as a production system, of which a rule engine is a part.)
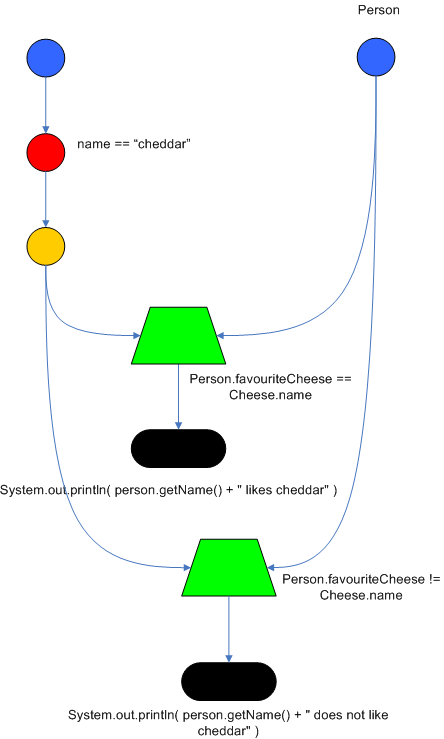
A rule engine is a computer program that relies on knowledge represented as rules, or productions, to make decisions based on information about a particular problem, which is provided by the user to the rule engine. This information is generally referred to as facts, which represent the current state. Rules take the form "If x, then do y." That is, they consist of two parts: a conditional part, also called the "if" part, and a consequent part, also called the "then" part. The "if" is followed by some statements in first-order or predicate logic, and the "then" part is followed by some imperative statements or commands.
Before getting too in-depth, one example of how a rule engine might be used is to aid nurses in making preliminary diagnoses of various respiratory illnesses. The rules would encode knowledge that an experienced doctor might also use to make such diagnoses, and would most likely have been written with the help of such a doctor. The nurse would first input, to our example rule engine program, physical information about the patient to be diagnosed, such as his age, current symptoms, and medical history. The rule engine would then compare these facts with the rules using any number of algorithms. For instance, one rule might specify that if the patient had worked in a coal mine and certain characteristic spots appear in the patient's x-rays, then a possible diagnosis is that he has black lung disease.
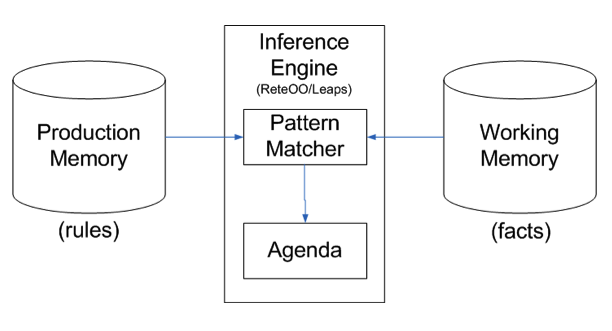
Although we tend to use "rule" engine as an all-encompassing term, it is closer to correct to say that a rule engine is one component of a production system. The production system also consists of a working memory, which is used to store the facts, as well as place for storing rules, called a production memory. The rule engine contains the functionality that matches the rules and the facts and determines the path of execution. An overview of this architecture, taken from the Drools documentation, is shown below.
Rule engines can implement forward-chaining algorithms, backward-chaining algorithms, or both. Briefly, a forward-chaining algorithm is driven by data, whereas a backward-chaining algorithm is driven by goals. In the former case, the data, or facts, are matched to rules until the conclusion is reached in which all rules that can execute have executed. In the latter, the rule engine begins with the desired conclusion, or goal, and attempts to find facts that can satisfy that goal. Here we focus on forward-chaining.
When a rule engine is run under the forward-chaining method, it goes through three main stages:
-
Match the rules with the facts by testing the conditional part of every rule with all subsets of facts. As a rule can match with more than one set of facts, pairs of rules and fact subsets are denoted instantiations. In Drools, they are referred to as Activations. The set of instantiations is sometimes called the conflict set.
-
Select and order the instantiations or Activations for execution. In Drools, the Activations selected are placed on an Agenda for execution.
-
Execute the rules in the order specified. Rule execution may trigger other programs, or may also update the facts, requiring rules to be re-matched.
The rule engine iterates through these stages until no further rules are matched.

Drools is an open source Java based implementation of a rule engine. It implements forward-chaining. Drools uses a variation of the Rete algorithm to match facts and rules. Although we won't go into too much detail here, a the Rete algorithm generally consists of building a network of nodes in which each node, except the root, corresponds to some logical phrase or pattern in the conditional portion of a rule. Facts are propagated through this network such that if a fact causes the pattern of a node to be true, it moves to the next node or nodes. When a terminal node is reached by a fact or set of facts, that rule is scheduled to be executed. A sample Rete network (from the Drools documentation) is shown below.
It is interesting to note that the Rete algorithm is generally believed to sacrifice memory for speed.
The execution of Drools generally goes through the same stages described above. The architecture of Drools is split into two main parts: rule authoring and runtime execution. The authoring and runtime components (again from the Drools documentation) are shown below.
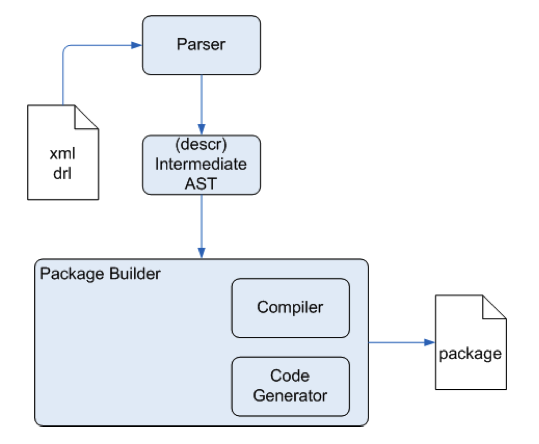
Authoring
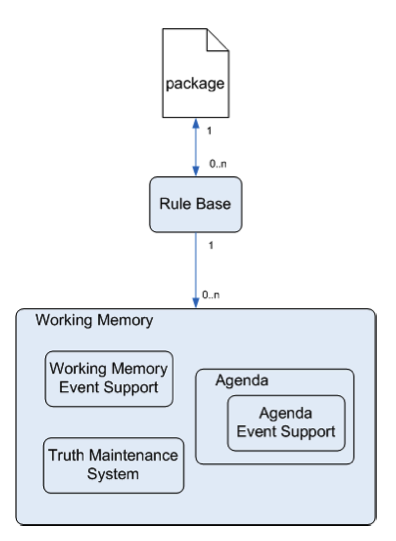
Runtime
Interested readers are encouraged to peruse the Drools documentation on the website. It is very thorough and quite helpful.
In certain cases, the use of a rule engine has several advantages over traditional algorithmic approaches; here we name a few that are relevant to our policy-driven data management concerns.
-
The use of a rule engine is more flexible for applications whose logic changes frequently. The problem the application addresses may or may not be complex, but rule engines are useful in such cases where an algorithmic approach would be too fragile, or would break easily if changed. This is often the case for business rules, as well as policies for VO's.
-
The rules of the rule engine, along with logging features, provide additional documentation in that it can show what decisions were made and why. It also centralizes the knowledge or logic behind the application, which is also useful for documentation purposes. When it comes to data management, documentation, or metadata, regarding how the data were created and processed is called provenance information.
-
There are many domain experts or administrators who are not computer savvy. For example,various scientists or administrators in a VO who may know what they want to do to store, share, and access their data, but not how best to do it.
-
Rules allow you to say what must be done in a declarative manner, as opposed to how to do it. Policies, which also specify what must be done and not necessarily how, can be readily characterized as rules.